Willkommen zu Krasse Links No 56. Rendert eure KIs souverän, heute plappern wir die Machtvergessenheit des Tech-Faschismus zur gemeinsamen Wirklichkeit.
Laut Heise will Merz mit dem amerikanischen Chipshersteller Nvidia eine „souveräne“ KI-Gigafabrik (früher: Rechenzentrum) bauen.
Konkret hat Huang laut der Bundesregierung zugesagt, dass Nvidia im Rahmen der Zusammenarbeit „moderne KI-Hardware, Softwarelösungen und fachliches Know-how bereitstellen“ wird. Gemeinsam mit deutschen Wirtschaftspartnern werde der US-Konzern in eine IT-Infrastruktur in Deutschland investieren, die sich in besonderem Maße an den Bedarfen der hiesigen Industrie orientiert. Alle Beteiligten legten dabei „besonderen Wert auf Sicherheitsstandards und Datenhoheit“.
Im Rahmen der Initiative für eine „Industrial AI Cloud“ werde Nvidia „mindestens eine KI-Gigafabrik in Deutschland realisieren“, heißt es aus Berlin. Partner für dieses Auftaktprojekt ist die Deutsche Telekom. Sie verkündete parallel, gemeinsam mit Nvidia „die weltweit erste industrielle KI-Cloud für europäische Hersteller auf deutschem Boden“ bis spätestens 2026 zu errichten. Diese soll innerhalb der nächsten neun Monate mit einer Kapazität von mindestens 10.000 GPUs (Graphics Processing Units) entstehen und auch Start-ups sowie Forschungseinrichtungen zugänglich sein. Die Regierung sieht das Vorhaben „als komplementär zur EU-Initiative zur Errichtung von KI-Gigafabriken“.
Anlässlich eines ähnlichen Deals mit den Vereinigsten Arabischen Emiraten schreibt Nathan Benaich In Fortune über das Souveränitäts-Paradox:
The United Arab Emirates is spending $20 billion on OpenAI’s Stargate UAE. The project is billed as a sovereign AI capability, yet it relies entirely on American chips, software, and infrastructure. This is the sovereign AI paradox: The harder nations push for AI independence, the deeper their dependencies become.
The UAE is not alone. From Paris to New Delhi, governments are pouring billions into so-called “sovereign” frontier models. France backs Mistral. India promotes BharatGPT. Each promises strategic autonomy yet is dependent on a globalized stack.
The term “AI factories,” adopted by Nvidia CEO Jensen Huang, rebrands data centers as strategic infrastructure akin to power plants or shipyards. This is political branding, not technical reality. It aligns AI with the rhetoric of national self-reliance, even as the underlying systems remain foreign-made and globally entangled. Calling any national data center an “AI factory” does not make it sovereign any more than France’s Qwant became a European search engine by wrapping Microsoft Bing. […]
Model weights, once seen as crown jewels, now update faster than policy cycles. They are versioned, cloned, and surpassed in quarterly releases. What endures is the infrastructure: chips, data pipelines, and labor required to build, deploy, and serve models. Sovereignty at the top of the stack is symbolic if the foundations remain foreign.
– The deepest dependencies lie in the invisible layers. Training data is often annotated by outsourced labor abroad, while pipelines for filtering and tuning rely on proprietary U.S. tools that entrench vendor lock-in. As AI moves into complex fields like law and medicine, demand is shifting toward expert labor in developed markets. Yet owning weights while depending on fragmented global workforces and imported toolchains is hardly sovereignty—it is a repackaged dependency.This reveals a new kind of digital colonialism. Not one where countries are denied access, but one where they are structurally bound into dependencies across every layer of the AI stack. A European lab may host its own weights on a data center in France, but that center runs on American hardware, software, and middleware. The illusion of control masks a dense web of interdependence. […]
Sovereign AI reflects a fundamental misunderstanding of modern technology. Unlike oil or steel, AI depends on global flows of data, chips, software, and talent. No country can meaningfully isolate itself. Sovereignty, pursued at the top of the stack, risks becoming a costly illusion.
Oder man könnte sich ja mal zurücklehnen und sagen, dass man gar nicht jeden Scheiß mitmachen muss?
Der Youtube Channel „The Stories We Tell“ hat einen sehenswerten Videoessay zum Thema Tech-Faschismus.

Ich sehe den Techfaschismus noch in der Verpuppungsphase, aber es kommen bereits viele Erzählungen zusammen, die in einandergreifen und sich gegenseitig verstärken: Die Ideologie um TESCREAL, Marsmission, Longtermism und Künstliche Intelligenz. Dazu die Narrative um geopolitische Vorherrschaft, Systemkonkurrenz zu China und dass der nächste Krieg „mit KI gewonnen“ wird.
Und das alles bildet nur den Hintergrund für die konkrete Machtübernahme der Broligarchs auf drei strategischen Ebenen:
- Das algorithmische Management der (digitalen) Öffentlichkeit.
- Die Positionierung eigener Leute in Schlüsselpositionen der Trump-Administration, inklusive Projekte wie DOGE.
- Die Positionierung von SpaceX, Starlink, Palantir und Aduril als der neue Military Industrial Complex.
Öffentlichkeit, Sicherheit und „Effizienz“. Alles aus einer Hand und eingebettet in einer sinnstiftenden Erlösungserzählung.
Donald Trump ist nur der Opa, der das TV anschreit, während die Macht und der Einfluss der Broligarchs mit der zunehmenden Verschmelzung ihrer Infrastrukturen mit dem Staat täglich wächst.
Ich war zu einem ähnlichen Thema in Anne Helms neuen Podcast: All das und viel mehr. Ich fordere die Abschaltung von X und rante über die Macht der Plattformen. Den Podcast kann man hier hören.
Vielen dank, dass Du Krasse Links liest. Da steckt eine Menge Arbeit drin und bislang ist das alles noch nicht nachhaltig finanziert. Letzten Monat kam ich unter € 400,- von den angestrebten 1.500,-. Mit einem monatlichen Dauerauftrag kannst Du helfen, die Zukunft des Newsletters zu sichern. Genaueres hier.
Michael Seemann
IBAN: DE58251900010171043500
BIC: VOHADE2H
M. Gessen analysiert in der New York Times die Hilflosigkeit, mit der die Amerikaner*innen auf die Erlaubnis-Erdbeben aus Mar-a-lago reagieren.
The United States in the last four months has felt like an unremitting series of shocks: executive orders gutting civil rights and constitutional protections; a man with a chain saw trying to gut the federal government; deliberately brutal deportations; people snatched off the streets and disappeared in unmarked cars; legal attacks on universities and law firms.
They kann dabei auf die eigenen Erfahrungen mit Putins Machtübernahme zurückgreifen, die they live miterlebt hat. Einmal genommene Erlaubnisse werden erwartet und mit jeder Erlaubnis gibt es immer weniger, das einen überrascht.
In this country, too, fewer and fewer things can surprise us. Once you’ve absorbed the shock of deportations to El Salvador, plans to deport people to South Sudan aren’t that remarkable. Once you’ve wrapped your mind around the Trump administration’s revoking the legal status of individual international students, a blanket ban on international enrollment at Harvard isn’t entirely unexpected. […]
We humans are stability-seeking creatures. Getting accustomed to what used to seem unthinkable can feel like an accomplishment. And when the unthinkable recedes at least a bit — when someone gets released from detention (as the Columbia University student Mohsen Mahdawi was a few weeks ago) or some particularly egregious proposal is withdrawn or blocked by the courts (as the ban on international students at Harvard has been, at least temporarily) — it’s easy to mistake it for proof that the dark times are ending. […]
And so just when we most need to act — while there is indeed room for action and some momentum to the resistance — we tend to be lulled into complacency by the sense of relief on the one hand and boredom on the other.
Raul Zelik in Analyse und Kritik mit vier Beobachtungen zum Faschismus:
Erstens: Der Prozess der Faschisierung lässt sich nicht auf den Aufstieg rechtsextremer Bewegungen reduzieren, die »Demokratie« und »Rechtsstaat« vom Rand her gefährden. Viel plausibler ist, dass es sich um eine Vertiefung bestehender Herrschaftsverhältnisse handelt, bei der die Selbstbeschränkung souveräner Gewalt (die so charakteristisch ist für das Entstehen liberaler »Gouvernementalität«) angesichts einer Krise aufgehoben wird.
Zweitens: Wesentliche Voraussetzung für diesen Prozess ist eine gesellschaftliche Mobilisierung, bei der ein Konsens darüber hergestellt wird, dass in Anbetracht eines – meist inneren – Feindes Grundrechte suspendiert werden können. Die Verteidigung »der Demokratie« oder »der Staatsräson« kann bei der Herstellung dieses Konsenses sogar noch erfolgreicher sein als die Anrufung von »Rasse« und Nation. Entscheidend ist, dass exekutive, legislative, judikative und mediale Macht an einem Strang ziehen. Es ist das, was gemeinhin als »Gleichschaltung« bezeichnet wird.
Drittens: Vor diesem Hintergrund muss man der Vorstellung, bei Faschismus und Liberalismus handele es sich um Antipoden, scharf widersprechen. Viel plausibler ist, von einem Kontinuum zwischen liberaldemokratischer Normalität und faschistischer Ausnahme auszugehen, wie es der Historiker Ishay Landa ideologiegeschichtlich oder die Ökonomin Clara Mattei anhand der Wirtschaftspolitik Großbritanniens und Italiens der Zwischenkriegszeit rekonstruiert haben.
Viertens: Zentrale Treiber der Faschisierung sind nicht selten die Gewaltapparate des Rechtsstaats selbst: Polizei, Armee, Geheimdienste, Justiz. In Spanien lässt sich dieser Zusammenhang empirisch übrigens bestens nachweisen: Nirgendwo sind die Stimmanteile der rechtsextremen Vox so hoch wie in Wahlbezirken mit Wohnkasernen der Guardia Civil. Diese Beobachtung bestätigt eine zentrale abolitionistische These, der zufolge eine Voraussetzung für Emanzipation der Rückbau der staatlichen Gewaltapparate ist. Eine Verteidigung von Grundrechten mit polizeilichen Mitteln ist zum Scheitern verurteilt – was grundsätzliche Fragen zur Kampagne für ein AfD-Verbot aufwirft.
In eine ähnliche Kerbe schlägt auch Alberto Toscano im ND mit Berufung auf George Jackson, Angela Davis und Herbert Markuse.
Nichtsdestotrotz ist aufschlussreich, dass der Faschismus für Jackson – ähnlich wie in Nicos Poulantzas’ Analyse in Faschismus und Diktatur – nicht direkt auf eine aufstrebende revolutionäre Kraft reagiert; er ist eher eine Art verspätete Konterrevolution, die von der Schwäche oder Niederlage der antikapitalistischen Linken profitiert. […]
Die »Gegenbewegung zu einer schwachen sozialistischen Revolution« ist in diesem Sinne ein gemeinsames Merkmal verschiedener Formen von Faschismus (Jacksons historische Anspielung lässt sich auch als Kritik an der heutigen Linken lesen). Kurzum: »Der Faschismus muss als episodisch notwendiges Stadium der sozioökonomischen Entwicklung des Kapitalismus während einer Krise betrachtet werden. Er ist Ergebnis eines schwachen und fehlgeschlagenen revolutionären Impulses – eines Bewusstseins, das einen Kompromiss (mit den bestehenden Machtverhältnissen, Anm.d.Übs.) eingegangen ist.«
Nimmt man diesen Gedanken ernst, dann ist der Faschismus keine Reaktion, keine Reaktanz, kein Backlash – oder zumindest kein Backlash gegen etwas Reales – sondern eine Antizipation der Schwäche von Links durch die Herrschende Klasse, die diese als Pfadgelegenheit zur „präventiven Revolution“ nutzt.
(Angela) Davis übernahm und adaptierte diese Terminologie von ihrem früheren Lehrer Herbert Marcuse, der 1970 in einem Interview mit Hans Magnus Enzensberger vorgeschlagen hatte, die gemeinhin akzeptierte politische Sequenz umzudrehen, wonach der Faschismus hinsichtlich sowohl seiner gesellschaftlichen Inhalte als auch seiner temporalen Form als reaktiv betrachtet werden müsse – entweder als unmittelbare Antwort auf einen potenziell siegreichen revolutionären Aufstand oder, vermittelt, auf bereits besiegte oder abklingende antikapitalistische Kämpfe. Es sei nicht die Reaktion, sondern die Antizipation, die den Faschismus in neuer Gestalt zum Leben erwecke.[…]
Die Frage nach der möglichen Durchsetzung des Faschismus in den USA, die in den 1970er und 1980er Jahren in den Befreiungsbewegungen und der radikalen Linken breit diskutiert wurde, ist für Marcuse eng mit den konkreten Formen der »präventiven Gegenrevolution« und mit den spezifischen Modalitäten »präventiver Gegengewalt« verschränkt. Die Besonderheit dieser antizipatorischen Logik hat auch viel mit den Unterschieden zwischen dem »aufkeimenden Faschismus« und dessen Vorläufern während der europäischen Zwischenkriegszeit zu tun.[…]
Dabei ist es gar nicht so relevant, dass sich die Gegenrevolution gegen einen imaginierten Feind wendet. Marcuse zu Enzensberger:
»Ich glaube, dass es so etwas wie einen präventiven Faschismus gibt. Wir haben in den letzten zehn bis zwanzig Jahren eine präventive Gegenrevolution erlebt, zur Abwehr einer Revolution, die gefürchtet wird, die aber gar nicht stattgefunden hat und die auch im Augenblick nicht auf der Tagesordnung steht. Auf dieselbe Weise entsteht auch der präventive Faschismus.«
Dylan Rodriguez sieht dementsprechend im Faschismus die Wiederherstellung liberaler Vorherrschaft:
»Wie würde sich unser Verständnis der Vereinigten Staaten verändern, wenn wir den Faschismus als Wiederherstellung liberaler Vorherrschaft und als Ausweg aus der Krise und eben nicht als Krisensymptom oder als Kollaps von ›Demokratie‹ und ›Zivilgesellschaft‹ begreifen?«
Infrastrukturvergessenheit des Individuums tritt oft in Form von Machtvergessenheit auf, wie Johannes Franzen anhand unserer schlimm „gesilencenten“ Medienmänner: Ulf Poschard, Richard David Precht, Boris Palmer, Markus Lanz und Dieter Nuhr anschaulich zeigt.
Die Fiktion einer diskursiven Übermacht von links, die man schwer beweisen kann und auch nicht beweisen muss, ermöglicht es Männern wie Nuhr, Lanz oder Precht, sich in eine Opferposition zu begeben, in der sie sich als heroische Außenseiter inszenieren können.
Das funktioniert, weil wir uns im Zeitalter einer allgemeinen Machtvergessenheit befinden. Damit meine ich eine gesellschaftlich weit verbreitete Unfähigkeit, einzuschätzen, wer tatsächlich Macht besitzt und wer nicht. […]
Ein perfektes Beispiel für Machtvergessenheit lieferte Lanz nur kurze Zeit später in seiner Sendung, die das Thema „Meinungsfreiheit“ noch einmal für das ZDF-Publikum aufbereitete. Eingeladen waren unter anderem der Tübinger Bürgermeister Boris Palmer und Ulf Poschardt, langjähriger Chefredakteur und derzeit Herausgeber der „Welt“-Gruppe. Beide klagen bei jeder Gelegenheit verlässlich darüber, dass die Meinungsfreiheit eingeschränkt werde. […]
Poschardt steht gerade mit seinem Buch „Shitbürgertum“ auf der Bestsellerliste. Mit seiner Position bei Axel Springer ist er aber auch eine der mächtigsten Personen der deutschen Medienlandschaft. In einem umfangreichen Porträt, das zum Anlass der Veröffentlichung dieses Buches im „Spiegel“ veröffentlicht wurde, ging es unter anderem um seine beiden Ferraris und seine Villa am Berliner Schlachtensee. Es müsste also eigentlich für Gelächter sorgen, dass sich so ein Mann über bürgerliche Eliten und deren vermeintliche Diskursmacht beklagt. […]
Palmer wird an einer Stelle von Lanz gefragt, welches Wort er denn nicht sagen darf. Es ist tatsächlich: „Das N-Wort“. An dieser Stelle wird noch einmal mit erschreckender Deutlichkeit sichtbar, dass Palmer eine ganze politische Identität darauf aufgebaut, ein rassistisches Schimpfwort nicht verwenden zu dürfen. Daraus konstruiert er eine ganze Gesellschaftsdiagnose. Wie das konkret aussieht, konnte man 2023 bei einer Veranstaltung an der Universität Frankfurt beobachten. Demonstranten hatten diese wegen Palmers Verwendung des N-Worts gestört, woraufhin er der Gruppe zurief: „Das ist nichts anderes als der Judenstern. Und zwar, weil ich ein Wort benutzt habe, an dem ihr alles andere festmacht. Wenn man ein falsches Wort sagt, ist man für euch ein Nazi.“
Wenn sich mächtige Menschen als Opfer inszenieren hat das nicht nur mit unreflektierter und gekränkter Eitelkeit zu tun, sondern hat natürlich auch eine ganz handfeste machtstabilisierende Funktion.
Die Machtvergessenheit im (medialen) Diskurs über Meinungsfreiheit hilft Ferrari-Besitzern, vermögenden Autoren und Oberbürgermeistern, sich mit der Klage über „soziale Kosten“ den Status von gesellschaftlichen Außenseitern und Nonkonformisten zu erschwindeln. Wenn man aber von der dröhnenden Debatte einmal einen Schritt zurücktritt, dann klingen „soziale Kosten“ verdächtig nach dem, was man früher schlicht als „Konsequenzen“ für das eigene Tun und Reden bezeichnet hätte.
Und darum geht es eigentlich: Menschen, die nach allen soziologischen Kategorien zur Elite des Landes gehören, wollen sprechen, aber nicht hören, wollen kritisieren, aber nicht kritisiert werden. Wenn sie austeilen, dann ist das Meinungsfreiheit, wenn sie einstecken sollen, dann jammern sie über „soziale Kosten“. Das ist von Trumps Rhetorik, die nun rasch einer ausgedachten Linken in die Schuhe geschoben werden soll, nicht weit entfernt.
Es war wieder Otherwise Salon und dieses Mal hatten wir Arne Semsrott zu Gast, der es neben dem Management von Frag den Staat schaffte das wichtige Buch „Machtübernahme“ zu schreiben. Hier ein Mitschnitt der Veranstaltung.

Ich hatte die Gelegenheit einmal kurz die Ereignisse und Deutungen zu DOGE zusammenzufassen, bevor Arne über die Machtübernahme sprach und dann moderierte Susann Kabisch zu der Frage, ob sowas wie DOGE auch in Deutschland möglich ist.
Joan Westenberg sieht die USA bereits als verdeckter „Failed State“ mit gutem Branding.
The facades are intact. The flags wave. The elections proceed. The agencies function. But beneath it all, an administrative sclerosis has set in, accumulating like plaque in the arteries of the state. The system hasn’t crashed. It’s coagulated.
This is how decline manifests in developed nations: not with explosions, but with bottlenecks. Not with fire, but with forms.Collapse doesn’t always arrive as spectacle. Sometimes it arrives as stagnation, repeated so often it becomes tradition. Institutions persist in form but erode in function. Capacity degrades incrementally, unnoticed, until dysfunction is mistaken for normalcy – until people begin to believe this is just how things work.
By the standards of political science – loss of state capacity, erosion of legitimacy, failure to deliver basic services – the United States has already failed. Not theoretically. Operationally. The only thing keeping the system upright is the myth that it can’t fall.
Wie schon Milan Kundera bemerkte, ist der Zusammenbruch eines Imperiums immer zuerst ein semantischer.
In some simulations, America is an empire. In others, a failed experiment. In others still, a corporation with a military. These simulations do not resolve. They coexist, and in doing so, render collective action impossible.
What happens when a country cannot update its shared reality? When every major institution is in epistemic freefall? When its myths are pristine, but its outputs are broken?
The answer: it keeps going. Until it can’t.
Charley Warzel beklagt im Atlantic das Abhandenkommen einer gemeinsamen Wirklichkeit in den USA.
On Tuesday, one of the top results for one user’s TikTok search for Los Angeles curfew was an AI-generated video rotating through slop images of a looted city under lockdown. Even to the untrained eye, the images were easily identifiable as AI-rendered (the word curfew came out looking like ciuftew). Still, it’s not clear that this matters to the people consuming and sharing the bogus footage. Even though such reality-fracturing has become a load-bearing feature of our information environment, the result is disturbing: Some percentage of Americans believes that one of the country’s largest cities is now a hellscape, when, in fact, almost all residents of Los Angeles are going about their normal lives. […]
The distortions are everywhere: People mainlining fascistic AI slop are occupying an alternate reality. But even those of us who understand the complexity of the protests are forced to live in our own bifurcated reality, one where, even as the internet shows us fresh horrors every hour, life outside these feeds may be continuing in ways that feel familiar and boring. We are living through the regime of a budding authoritarian—the emergency is here, now—yet our cities are not yet on fire in the way that many shock jocks say they are.
Unter anderem diesen Text aufgreifend versucht auch Ryan Broderick unseren weirden medial-politischen Moment zu fassen.
It doesn’t matter if anyone believes the unreality of what they’re seeing online. Misinformation and disinformation don’t actually need to convince anyone of anything to have an impact. They just need to make you question what you’re seeing. The Big Lie and the millions of small ones online, whatever they happen to be wherever you’re living right now, just have to cause division. To wear you down. To provide an opening for those in power, who now have both too much of it and too few concerns about how to wield it. The populist demagogues and ravenous oligarchs the internet gave birth to in the 2010s are now firmly at the helm of the global order and, also, hooked up to the same chaotic, emotionally-gratifying global information networks that we all are, both social and, now, AI-generated. And, also like us, they are being heavily influenced by them in ways we can’t totally see or predict. Which is how we’ve ended up in a place where missiles are flying, planes are dropping out of the sky, and vulnerable people are being thrown in gulags, all while our leaders are shitposting about their big, beautiful plans for more extrajudicial arrests and genocidal territorial expansion. Assured by mindless AI chatbots that their dreams of world domination and self-enrichment are valid and noble and righteous. And there is no off ramp there. Everyone, even the folks with the nuclear codes, is entertaining themselves online as the world burns. Posting through it and monitoring the situation until it finally reaches their doorstep and forces them to look up from their phone and log off.
Letzte Woche wurde ein neue Paper von Apple heiß diskutiert, das ein weiteres mal zeigt, dass LLMs nicht „denken“(/reason).
Diesmal zeigen sie das anhand des plötzlichen Scheiterns von LLMs beim Lösen des Tower of Hanoi-Spiels ab einer bestimmten Komplexitätsstrufe.
Our empirical investigation reveals several key findings about current Language Reasoning Models (LRMs): First, despite their sophisticated self-reflection mechanisms learned through reinforcement learning, these models fail to develop generalizable problem-solving capabilities for planning tasks, with performance collapsing to zero beyond a certain complexity threshold. Second, our comparison between LRMs and standard LLMs under equivalent inference compute reveals three distinct reason- ing regimes (Fig. 1, bottom). For simpler, low-compositional problems, standard LLMs demonstrate greater efficiency and accuracy. As problem complexity moderately increases, thinking models gain an advantage. However, when problems reach high complexity with longer compositional depth, both model types experience complete performance collapse (Fig. 1, bottom left). Notably, near this collapse point, LRMs begin reducing their reasoning effort (measured by inference-time tokens) as problem complexity increases, despite operating well below generation length limits (Fig. 1, bottom middle). This suggests a fundamental inference time scaling limitation in LRMs’ reasoning capabilities relative to problem complexity. Finally, our analysis of intermediate reasoning traces or thoughts reveals complexity-dependent patterns: In simpler problems, reasoning models often identify correct solutions early but inefficiently continue exploring incorrect alternatives—an “overthinking” phenomenon. At moderate complexity, correct solutions emerge only after extensive exploration of incorrect paths. Beyond a certain complexity threshold, models completely fail to find correct solutions (Fig. 1, bottom right). This indicates LRMs possess limited self-correction capabilities that, while valuable, reveal fundamental inefficiencies and clear scaling limitations.
Das Paper wurde viel dafür kritisiert, dass es ja nicht neues zeige und ich kann mich dem anschließen. In Krasse Links No 27 schrieb ich bereits über den verfolgten Ansatz:
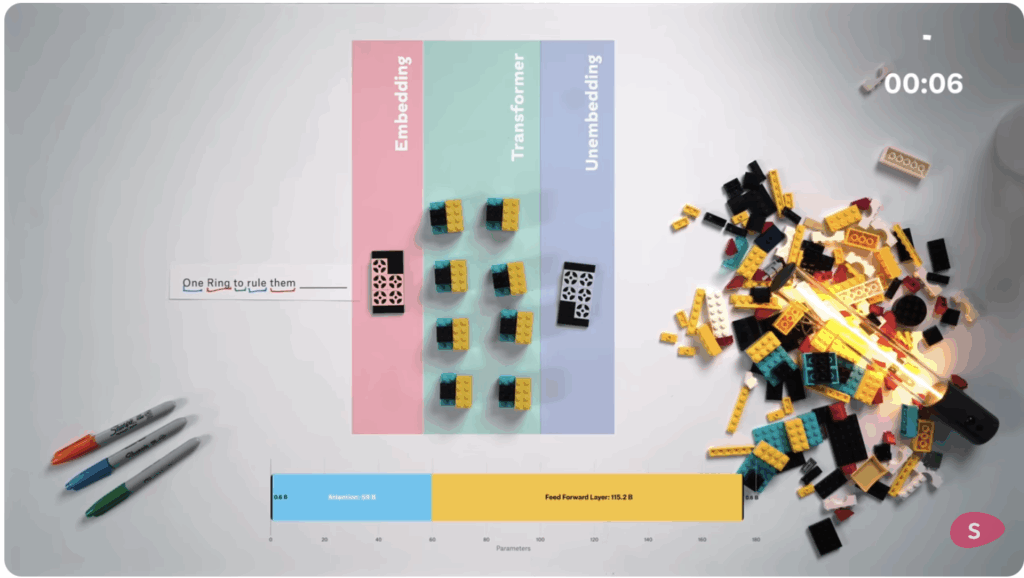
Um einmal zu verdeutlichen, was da genau passiert: es werden für alle möglichen Logik-, Zähl-, Mathe- und Rätsel-Beispielen Millionen, vllt Milliarden Semantikpfade im „tree sort“-Verfahren erkundet, um sich eine nach und nach vollständigere Bibliothek aller „richtigen“ Antwortpfade zu völlig egalen Fragen anzulegen. LLMs haben halt ein genauso großes Gedächtnis, wie Silicon Valley Geld hat, und das scheint auszureichen, einfach alle Lösungspfade durchzuprobieren und sich die richtigen einzuprägen. Und wenn man jetzt bedenkt, dass der dadurch erreichte Nutzen ein erweiterter, aber unzuverlässiger Taschenrechner ist, kommen mir die unfassbaren Ressourcen, die dafür gerade bewegt werden, immer bekloppter vor.
Wir wissen all das schon, aber niemand zieht Konsequenzen und der Grund dafür ist, dass man sich das alles trotz allem schön reden kann.
Jahaa, NOCH brechen sie ab einer bestimmten Komplexität ab, aber wenn wir erst noch 120 Regenwälder für Reinforcement Learning opfern, dann … dann.
Und klar, das ist Pattern Recognition aber unser Hirn macht doch auch Pattern Recognition?
Ganz anders: Aus der Warte von jemandem, der Denken beruflich macht, kann ich ziemlich sicher sagen: Das, was LLMs tun, ist kein denken.
Wenn man es schon mit menschlichen Tätigkeiten vergleichen will, gleicht es am ehesten dem Plappern.
Ihr kennt das: Man ist aufgefordert, sich zu einem Thema zu äußern, zu dem man einfach keine Meinung hat, aber sozialer Druck zwingt einen dazu.
Dann plappert man. Man rendert Tokens, die einzig den Sinn erfüllen, die Erwartungen des Gegenüber zu befriedigen.
Plappern ist das, was LLMs machen, auf einem sehr fundamentalen Level. Und egal wie viel Rechenpower man da noch reinversenkt:
Man kann Plappern nicht zu Denken skalieren.